Die API-Kosten für große Sprachmodelle (LLM) können durch die Implementierung von Semantic Caching erheblich gesenkt werden. Dies geht aus den Beobachtungen von Sreenivasa Reddy Hulebeedu Reddy hervor, einem Experten für maschinelles Lernen, der einen monatlichen Anstieg seiner LLM-API-Rechnung um 30 % feststellte. Reddy stellte fest, dass Benutzer dieselben Fragen auf unterschiedliche Weise stellten, was zu redundanten Aufrufen des LLM und unnötigen Kosten führte.
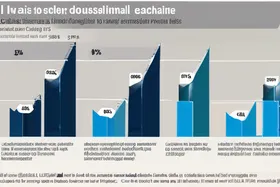
Reddy fand heraus, dass traditionelles Exact-Match-Caching, das den Abfragetext als Cache-Schlüssel verwendet, nur 18 % dieser redundanten Aufrufe erfasste. Beispielsweise würden Abfragen wie "Was sind Ihre Rückgabebedingungen?", "Wie kann ich etwas zurückgeben?" und "Kann ich eine Rückerstattung erhalten?" alle den Cache umgehen, obwohl sie die gleiche zugrunde liegende Bedeutung haben. "Benutzer stellen die gleichen Fragen auf unterschiedliche Weise", erklärte Reddy, "wodurch nahezu identische Antworten generiert werden, die jeweils die vollen API-Kosten verursachen."
Um dem entgegenzuwirken, implementierte Reddy Semantic Caching, das sich auf die Bedeutung der Abfragen und nicht auf deren exakten Wortlaut konzentriert. Dieser Ansatz erhöhte die Cache-Trefferrate auf 67 %, was zu einer Reduzierung der LLM-API-Kosten um 73 % führte. Semantic Caching nutzt Techniken der Verarbeitung natürlicher Sprache (NLP), um die Absicht hinter einer Abfrage zu verstehen und die entsprechende Antwort aus dem Cache abzurufen, selbst wenn die Abfrage anders formuliert ist.
Der Anstieg der LLM-API-Kosten ist ein wachsendes Problem für Unternehmen und Entwickler, die KI-gestützte Anwendungen nutzen. Da LLMs zunehmend in verschiedene Dienste integriert werden, wird die Optimierung der API-Nutzung und die Reduzierung der Kosten entscheidend. Semantic Caching bietet eine potenzielle Lösung, indem es redundante Berechnungen minimiert und die Effizienz verbessert.
Die effektive Implementierung von Semantic Caching erfordert jedoch sorgfältige Überlegungen. Naive Implementierungen können Nuancen in der Sprache übersehen und die Bedeutung von Abfragen nicht genau erfassen. Ausgefeilte NLP-Modelle und sorgfältiges Tuning sind oft notwendig, um eine optimale Leistung zu erzielen. Die spezifischen Techniken, die für Semantic Caching verwendet werden, können variieren, beinhalten aber im Allgemeinen das Einbetten von Abfragen in einen Vektorraum und die Verwendung von Ähnlichkeitsmetriken, um semantisch ähnliche Abfragen zu identifizieren.
Die Entwicklung von Semantic Caching unterstreicht die laufenden Bemühungen, die Effizienz und Kosteneffektivität von LLMs zu verbessern. Da die KI-Technologie immer weiter fortschreitet, werden Innovationen wie Semantic Caching eine wichtige Rolle dabei spielen, LLMs für ein breiteres Spektrum von Anwendungen zugänglicher und nachhaltiger zu machen. Die Auswirkungen gehen über Kosteneinsparungen hinaus und ermöglichen potenziell reaktionsschnellere und personalisierte Benutzererlebnisse, indem zwischengespeicherte Antworten für häufige Abfragen genutzt werden.


















Discussion
Join the conversation
Be the first to comment