
3 min
AI Insights31m ago
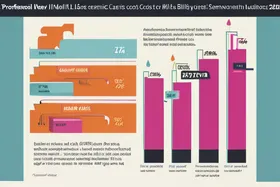
LLM-Kosten senken: Semantisches Caching reduziert Rechnungen um 73 %
Semantisches Caching, das sich auf die Bedeutung von Anfragen anstatt auf die exakte Formulierung konzentriert, kann die LLM-API-Kosten drastisch reduzieren, indem es Antworten auf semantisch ähnliche Fragen identifiziert und wiederverwendet. Durch die Implementierung von semantischem Caching erzielte ein Unternehmen eine Reduzierung der LLM-API-Kosten um 73 %, was die Ineffizienz des traditionellen Exact-Match-Caching bei der Handhabung der Nuancen von Benutzeranfragen und das Potenzial für erhebliche Kosteneinsparungen durch intelligentere Caching-Strategien verdeutlicht.

00











Discussion
Join the conversation
Be the first to comment