

3 min
AI Insights3h ago
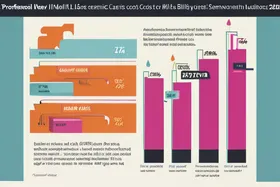
Slash LLM Costs: Semantic Caching Cuts Bills by 73%
Semantic caching, which focuses on the meaning of queries rather than exact wording, can drastically reduce LLM API costs by identifying and reusing responses to semantically similar questions. By implementing semantic caching, one company achieved a 73% reduction in LLM API costs, highlighting the inefficiency of traditional exact-match caching in handling the nuances of user queries and the potential for significant cost savings through more intelligent caching strategies.

20











Discussion
Join the conversation
Be the first to comment