Selon Sreenivasa Reddy Hulebeedu Reddy, développeur d'applications d'IA, de nombreuses entreprises voient leurs factures d'interfaces de programmation d'applications (API) de grands modèles linguistiques (LLM) exploser, en raison de requêtes redondantes. Reddy a constaté que les utilisateurs posent souvent les mêmes questions de différentes manières, ce qui oblige le LLM à traiter chaque variation séparément et à encourir des coûts d'API complets pour chacune.
L'analyse des journaux de requêtes effectuée par Reddy a révélé que les utilisateurs posaient à plusieurs reprises les mêmes questions en utilisant un phrasé différent. Par exemple, des questions telles que "Quelle est votre politique de retour ?", "Comment puis-je retourner un article ?" et "Puis-je obtenir un remboursement ?" ont toutes suscité des réponses presque identiques de la part du LLM, mais chacune a déclenché un appel API distinct.
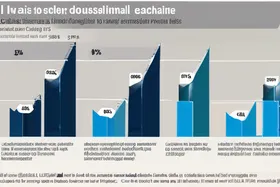
La mise en cache traditionnelle, basée sur la correspondance exacte, qui utilise le texte de la requête comme clé de cache, s'est avérée inefficace pour résoudre ce problème. Reddy a constaté que la mise en cache basée sur la correspondance exacte ne capturait que 18 de ces appels redondants sur 100 000 requêtes de production. "La même question sémantique, formulée différemment, contournait complètement le cache", a expliqué Reddy.
Pour lutter contre ce phénomène, Reddy a mis en œuvre la mise en cache sémantique, une technique qui met en cache les réponses en fonction du sens de la requête plutôt que du libellé exact. Cette approche a augmenté le taux d'accès au cache à 67 %, ce qui a entraîné une réduction de 73 % des coûts d'API du LLM. La mise en cache sémantique s'attaque au problème fondamental des utilisateurs qui formulent la même question de plusieurs manières.
La mise en cache sémantique représente une avancée significative par rapport aux méthodes de mise en cache traditionnelles dans le contexte des LLM. La mise en cache traditionnelle repose sur une correspondance exacte entre la requête entrante et la requête mise en cache. Cette méthode est simple à mettre en œuvre, mais ne parvient pas à saisir les nuances du langage humain, où la même intention peut être exprimée de nombreuses façons. La mise en cache sémantique, en revanche, utilise des techniques telles que les embeddings et les métriques de similarité pour déterminer si une nouvelle requête est sémantiquement similaire à une requête précédemment mise en cache. Si la similarité dépasse un seuil prédéfini, la réponse mise en cache est renvoyée, évitant ainsi un appel API coûteux.
Le développement de la mise en cache sémantique souligne le besoin croissant de méthodes efficaces et rentables pour utiliser les LLM. À mesure que les LLM sont de plus en plus intégrés dans diverses applications, la gestion des coûts d'API devient une préoccupation essentielle pour les entreprises. La mise en cache sémantique offre une solution prometteuse en réduisant la redondance et en optimisant l'utilisation des ressources. Des recherches et développements supplémentaires dans ce domaine pourraient conduire à des stratégies de mise en cache encore plus sophistiquées, qui minimiseraient davantage les coûts d'API des LLM et amélioreraient les performances globales.

















Discussion
Join the conversation
Be the first to comment